1. DEF: PDA
Automat z dodatkową pamięcią w postaci stosu (widać tylko ostatnio włożony symbol).
Automatem ze stosem nazywamy M=(Q,Σ,Γ,δ,q0,Z0,F), gdzie
- Q — skończony zbiór stanów
- Σ — alfabet wejściowy
- Γ — alfabet stosowy
- q0∈Q — stan początkowy
- Z0∈Γ — symbol początkowy na stosie
- F∈Q — zbiór stanów akceptujących (jeśli F=∅ to akceptujemy przez pusty stos)
- δ funkcja przejścia postaci: δ:Q×(Σ∪{ϵ})×Γ→2Q×Γ∗
1.1. DEF: Opis chwilowy automatu
— to trójka (q,α,γ), gdzie
- q∈Q — stan automatu
- α∈Σ∗ — nieprzeczytane jeszcze wejście
- γ∈Γ∗ — zawartość stosu (szczyt stosu z lewej strony)
1.2. DEF: Relacja przejścia w jednym kroku ⊢M
⊢∗ — zwrotne i przechodnie domknięcie ⊢,
⊢i — i-krotne złożenie ⊢.
- (q,aα,Zγ)⊢M(pi,α,γiγ) jeśli istnieje przejście δ(q,a,Z)={(p1,γ1),…,(pm,γm)} i wybraliśmy i-tą możliwość.
- (q,α,Zγ)⊢M(pi,α,γiγ) jeśli istnieje przejście δ(q,ϵ,Z)={(p1,γ1),…,(pm,γm)} i wybraliśmy i-tą możliwość.
1.3. Sposoby akceptowania słów języka
Język Akceptowany przez PDA M przy pustym stosie (F=∅) to N(M)={w∈Σ∗:∃p∈Q(q0,w,Z0)⊢∗(p,ϵ,ϵ)}
Język akceptowany przez PDA M przez stan końcowy to L(M)={w∈Σ∗:∃p∈F∃γ∈Γ∗(q,w,Z0)⊢∗(p,ϵ,γ)}
Oba sposoby akceptowania są równoważne.
2. Przykład
Palindrom z gramatyką S→0S0∣1S1∣#
- Automat startuje z pustym stosem i w stanie q1.
- Jeżeli jesteśmy w stanie q1 i na wejściu widzimy a∈{0,1} to wstawiamy a na stos, pozostajemy w stanie q1 i idziemy do następnego symbolu wejściowego.
- Jeżeli jesteśmy w stanie q1 i na wejściu widzimy # to przechodzimy do stanu q2 i idziemy do następnego symbolu wejściowego.
- Jeżeli jesteśmy w stanie q2 i na wejściu widzimy a∈{0,1} i na stosie jest także a to pozostajemy w stanie q2, ściągamy a ze stosu i idziemy do następnego symbolu wejściowego.
- Jeżeli jesteśmy w stanie q2, skończyliśmy czytać wejście i stos jest pusty, to akceptujemy słowo wejściowe.
- W każdym innym przypadku odrzucamy słowo wejściowe.
3. Przykład
Mamy maszynę M=({q1,q2},{0,1},{A,B,Z},δ,q1,Z,∅)
| q1 |
|
(q1,AA) |
(q1,AB) |
(q1,A) |
(q1,BA) |
(q1,BB) |
(q1,B) |
| q2 |
|
(q2,ϵ) |
— |
— |
— |
(q2,ϵ) |
— |
| q1 |
|
(q2,A) |
(q2,B) |
(q2,ϵ) |
| q2 |
|
— |
— |
— |
Przykładowo dla 0110:
(q1,0110,Z)⊢(q1,110,A)⊢(q1,10,BA)⊢(q2,10,BA)⊢(q2,0,A)⊢(q2,ϵ,ϵ)
Za to 110 nie należy do języka:
- (q1,110,Z)⊢(q1,10,B)⊢(q1,0,BB)⊢(q1,ϵ,ABB)⊢(q2,ϵ,ABB)⊢?
- (q1,110,Z)⊢(q1,10,B)⊢(q1,0,BB)⊢(q2,0,BB)⊢?
- (q1,110,Z)⊢(q1,10,B)⊢(q2,10,B)⊢(q2,0,ϵ)⊢?
- (q1,110,Z)⊢(q2,100,ϵ)⊢?
Oczywiście mamy język N(M)={wwR:w∈{0,1}∗}.
4. Deterministyczny PDA
PDA może być deterministyczny, jeśli w każdym przypadku możemy wykonać co najwyżej jedno przejście (czyli może też być zero przejść w przeciwieństwie do zwykłego DFA):
- ∀q∈Q∀Z∈Γδ(q,ϵ,Z)=∅⟹∀a∈Σδ(q,a,Z)=∅
- ∀q∈Q∀a∈Σ∪{ϵ}∀Z∈Γ∣δ(q,a,Z)∣≤1
Niestety takie DPDA są słabsze od PDA.
Np. język z przykładu nie jest rozpoznawalny przez żaden DPDA.
5. Twierdzenie: język bezkontekstowy ⟹ PDA
Jeśli L jest językiem bezkontekstowym to istnieje PDA M taki, że L=N(M).
5.1. D-d
Załóżmy, że L nie zawiera ϵ i jest zdefiniowany przez gramatykę bezkontekstową w postaci Greibach G=(N,T,P,S). Definiujemy PDA M następująco:
- M=({q},T,N,δ,q,S,∅)
- δ(q,a,A)={(q,γ):(A→aγ)∈P}.
M symuluje wprowadzenie lewostronne gramatyki G. Ponieważ G jest typu Greibach każdy kolejny napis w wyprowadzeniu lewostronnym ma formę xα, gdzie x∈T∗ oraz α∈N∗. Maszyna M przechowuje α na stosie po przeczytaniu przedrostka x.
Teraz d-d indukcyjny po długości wyprowadzenia (liczby kroków), że SG⇒∗⟺(q,x,S)M⊨∗(q,ϵ,ϵ)
5.2. Przykład
G=({A,B},{a,b},{A→aAB∣aB,B→b},A)
A więc M=({q},{a,b},{A,B},δ,q,A,∅)
| q |
|
(q,AB),(q,B) |
— |
— |
(q,ϵ) |
— |
— |
Czyli na przykład mamy:
A⇒aAB⇒aaBB⇒aabB⇒aabb.
I właśnie teraz równoważnie:
(q,aabb,A)⊢(q,abb,AB)⊢(q,bb,BB),⊢(q,b,B)⊢(q,ϵ,ϵ).
6. Twierdzenie: PDA ⟹ język bezkontekstowy
Jeśli L=N(M) dla PDA M to L jest językiem bezkontekstowym.
6.1. D-d
Weźmy PDA M=(Q,Σ,Γ,δ,q0,Z0,∅). Konstruujemy gramatykę bezkontekstową G=(N,Σ,P,S), gdzie
- N — zbiór obiektów postaci [q,A,p] (p,q∈Q,A∈Γ) oraz nowy symbol S
- P — zbiór produkcji postaci:
- S→[q0,Z0,q] dla każdego q∈Q
- [q,A,qm+1]→a[q1,B1,q2][q2,B2,q3]…[qm,Bm,qm+1] dla dowolnych q,q1,…,qm+1∈Q, dla każdego a∈Σ∪{ϵ} i dowolnych A,B1,…,Bm∈Γ takich, że (q1,B1,…,Bm)∈δ(q,a,A)
- [q,A,p]→a jeśli (p,ϵ)∈δ(q,a,A).
Wyprowadzenie lewostronne w G symuluje ruchy M na wejściu x.
[q,A,p] wyprowadza x⟺M będąc w stanie q i mając na stosie Aα po wczytaniu x znajdzie się w stanie p, na stosie będzie α i α nie była zmieniana i czytana w tym czasie.
Teraz dowód indukcyjny po liczbie kroków, że [q,A,p]G⇒∗x⟺(q,x,A)M⊢∗(p,ϵ,ϵ)
6.2. Przykład
Mamy M=({p,q},{a,b},{X,Z},δ,p,Z,∅)
| p |
|
(p,XX) |
(p,X) |
(q,ϵ) |
— |
— |
(q,ϵ) |
| q |
|
— |
— |
(q,ϵ) |
— |
— |
— |
Możemy powyższą tabelkę zapisać w następujący sposób:
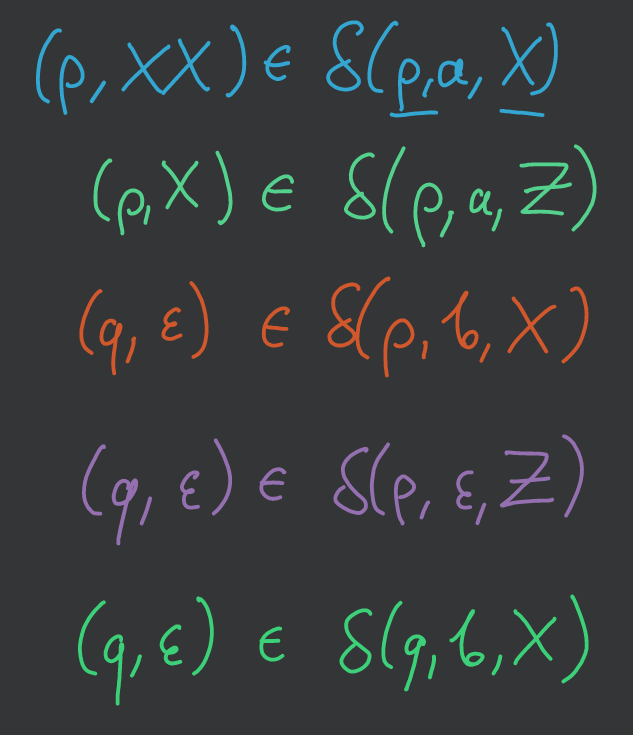
Tworzymy produkcje:
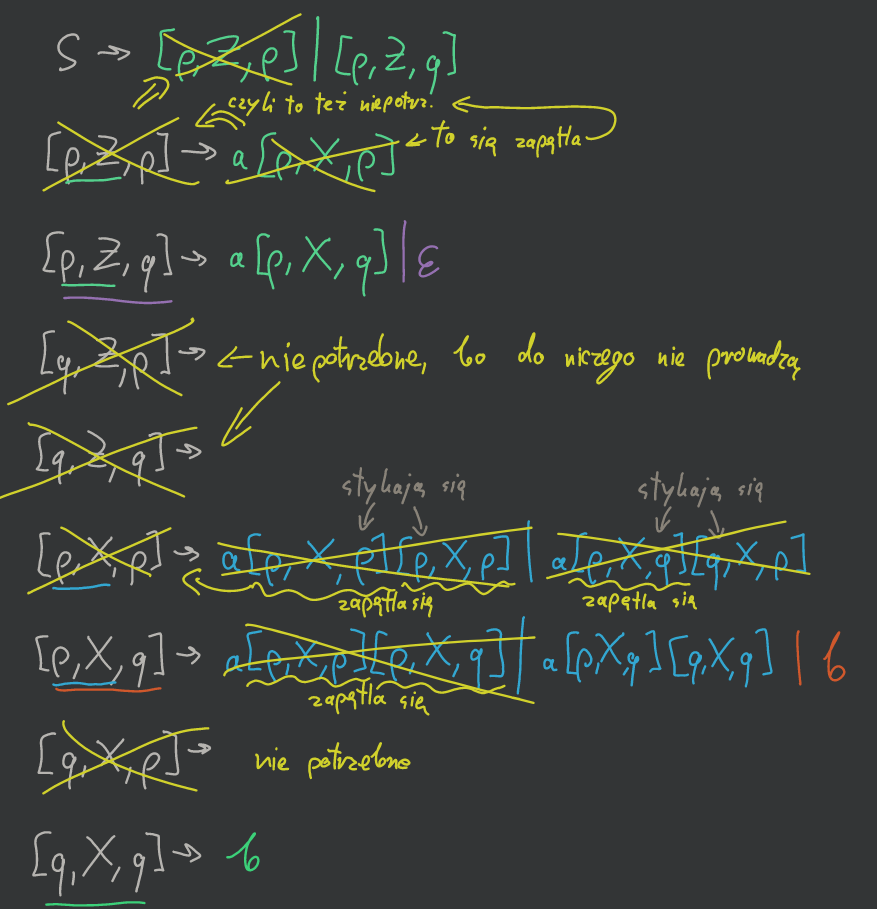
i od razu je „przetwarzamy” na podstawie funkcji przejścia δ i patrząc na dowód twierdzenia.
Następnie usuwamy niepotrzebne elementy, które albo się zapętlają, albo prowadzą do nikąd.