1. DEF
Gramatyka bezkontekstowe G to czwórka G=(N,T,P,S) gdzie
- N — skończony zbiór zmiennych (nieterminale)
- T — skończony zbiór symboli końcowych (terminale, alfabet)
- P — skończony zbiór produkcji postaci A→α , gdzie A∈N oraz α∈(N∪T)∗
- S∈N — symbol początkowy
2. Relacja wyprowadzenia G⇒
Jeśli A→β jest produkcją w G oraz α,γ∈(N∪T)∗ wówczas αAγG⇒αβγ.
(αβγ jest bezpośrednio wyprowadzany z αAγ w gramatyce G).
Notacja:
- Będziemy pisać tylko ⇒ gdy gramatyka jest oczywista.
- ⇒∗ — zwrotne i przechodnie domknięcie ⇒.
3. DEF: Język generowany przez G
L(G)={w:w∈T∗∧SG⇒∗w}.
Język L nazywamy bezkontekstowym jeśli jest identyczny z L(G) dla pewnej gramatyki bezkontekstowej G.
G1 i G2 są równoważne, jeżeli L(G1)=L(G2).
3.1. Przykład
G=( {S},{0,1},{S→ε,S→1,S→0S0,S→1S1},S ) lub inaczej (krócej) zapisując S→ϵ∣0∣1∣0S0∣1S1.
Wyprowadzenie słowa 0110: S⇒0S0⇒01S10⇒0110.
4. Drzewo wyprowadzania
Drzewo o następujących własnościach
- każdy wierzchołek ma etykietę z N∪T∪{ε}
- korzeń ma etykietę S (symbol początkowy)
- wierzchołki wewnętrzne mają etykiety z N
- jeżeli wierzchołek wewnętrzny ma etykietę A a jego potomkowie od lewej mają kolejno etykiety X1,…,Xn to A→X1…Xn jest produkcją w P
Jeśli konkatenacja wszystkich liści czytanych od lewej do prawej daje α to drzewo nazywamy drzewem wyprowadzenia α.
4.1. Przykład
kontynuacja przykładu wcześniejszego

4.2. Przykład
Mamy:
- gramatykę E→(E+E)∣(E∗E)∣id
- chcemy uzyskać id+id∗id

Jak widać, możemy uzyskać dwa drzewa dla tego słowa w tej gramatyce.
Oznacza to, że gramatyka jest niejednoznaczna.
5. Twierdzenie o istnieniu drzewa wyprowadzenia dla gramatyki G
Niech G=(N,T,P,S) będzie gramatyką bezkontekstową. Wówczas S⇒∗α⟺ istnieje drzewo wyprowadzenia α w gramatyce G.
5.1. D-d
«Indukcja względem liczby wierzchołków wewnętrznych w drzewie.»
5.2. DEF: Lewo- i prawostronne wyprowadzanie
Jeżeli w każdym kroku wyprowadzenia stosujemy produkcję do nieterminala leżącego najbardziej na lewo (prawo), to wyprowadzenie nazywamy lewostronnym (prawostronnym). Jeżeli w∈L(G) to w ma co najmniej jedno drzewo wyprowadzenia. Każdemu drzewu wyprowadzenia odpowiada dokładnie jedno wyprowadzenie lewostronne (prawostronne).
5.2.1. Przykład
kontynuacja przykładu wcześniejszego
- Lewostronne wyprowadzenie:
E⇒E+E⇒id+E⇒id+E∗E⇒id+id∗E⇒id+id∗E
- Prawostronne wyprowadzenie:
E⇒E+E⇒E+E∗E⇒E+E∗id⇒E+id∗id⇒id+id∗id
5.3. DEF: Gramatyka wieloznaczna
Jeśli L(G) istnieje słowo mające dwa różne drzewa wyprowadzenia to G nazywamy wieloznaczną (niejednoznaczną).
6. DEF: Symbole bezużyteczne
Symbol X jest użyteczny, jeśli istnieje wyprowadzenie postaci S⇒∗αXγw gdzie w∈T∗
otherwise X jest bezużyteczny.
Niech L — niepusty język bezkontekstowy, wówczas L można wygenerować za pomocą gramatyki G o następujących własnościach:
- każdy symbol pojawia się w wyprowadzeniu jakiegoś słowa z L
- nie ma produkcji postaci A→B (produkcje jednostkowe), gdzie A,B∈N
Co więcej, jeśli ε∈/L to w G nie ma produkcji postaci A→ε.
7. Lemat o usuwaniu symboli bezużytecznych#1
Dla dowolnej gramatyki bezkontekstowej G=(N,T,P,S) z L(G)=∅ można efektywnie znaleźć równoważną gramatykę bezkontekstową G′=(N′,T,P′,S) taką, że dla dowolnego A∈N′ istnieje w∈T∗ takie, że A⇒∗w.
7.1. D-d (szkic)
- NS←∅
- Nn←{A:(A→w)∈P∧w∈T∗}
while NS=Nn:
- NS←Nn
- Nn←NS∪{A:(A→α)∈P∧α∈(T∪NS)∗}
- N′←Nn
- P′←{(A→α)∈P:A∈Nn∧α∈(T∪NS)∗}
8. Lemat o usuwaniu symboli bezużytecznych#2
Dla dowolnej gramatyki bezkontekstowej G=(N,T,P,S) można efektywnie znaleźć równoważną gramatykę bezkontekstową G′=(N′,T′,P′,S) taką, że dla każdego X∈(N′∪T′) istnieją α,β∈(N′∪T′)∗ takie, że S⇒∗αXβ.
8.1. D-d (szkic)
- N′←{S}
while można zmienić N′:
- Jeśli A∈N′ oraz A←α1∣…∣αn to dodaje wszystkie nieterminale z α1,…,αn do N′ a terminale do T′
- Do P′ przenieś tylko te produkcje z P, które zawierają symbole z N′∪T′∪{ε}.
9. Twierdzenie#2
Każdy niepusty język bezkontekstowy jest generowany przez gramatykę bezkontekstową niezawierającą symboli bezużytecznych.
10. Twierdzenie#3
Jeżeli L=L(G) dla gramatyki bezkontekstowej G=(N,T,P,S) to dla L∖{ε} istnieje gramatyka bezkontekstowa G′ niezawierająca ε-produkcji i symboli bezużytecznych.
10.1. D-d
Symbole bezużyteczne usunęliśmy dzięki poprzedniemu twierdzeniu.
Dla każdego nieterminala A sprawdzamy czy A⇒∗ε. Jeśli tak to każdą produkcję B→αAβ zastępujemy produkcjami B→αAβ oraz B→αβ (ale nie dołączamy B→ε).
Następnie usuwamy wszystkie ε-produkcje
11. Twierdzenie#4
Każdy język bezkontekstowy niezawierający ε jest definiowany za pomocą gramatyki niezawierającej symboli bezużytecznych, ε-produkcji oraz produkcji jednostkowych.
11.1. D-d
Jeżeli dla nieterminala A mamy A⇒∗B oraz A=B,
to dla każdej niejednostkowej produkcji B→α dodajemy produkcję A→α.
Następnie usuwamy produkcje jednostkowe.
12. Postać normalna Chomsky’ego
Dowolny język bezkontekstowy niezawierający ε jest generowany przez gramatykę, której wszystkie produkcje są postaci A→BC lub A→a, gdzie A,B,C∈N oraz a∈T.
12.1. D-d
Niech G będzie gramatyką bez symboli bezużytecznych, ε-produkcji i produkcji jednostkowych. Wówczas jeśli prawa strona produkcji jest długości 1 to jest postaci A→a.
Dla pozostałych produkcji wykonujemy następujące operacje:
- Jeśli po prawej stronie występuje terminal a to dodajemy do N nowy nieterminal Ca a do produkcji Ca→a i zastępujemy a przez Ca.
- Teraz jeśli prawa strona produkcji jest dłuższa niż 1 to zawiera tylko nieterminale. Jeśli jest postaci A→B1…Bn dla n>2, to tworzymy nowe nieterminale D1,…,Dn−2 i zastępujemy tę produkcję przez A→B1D1,D1→B2D2,…,Dn−3→Bn−2Dn−2,Dn−2→Bn−1Bn.

12.2. Przykład
Mamy:
- S→bA∣aB
- A→bAA∣aS∣a
- B→aBB∣bS∣b
Wówczas, postać normalna Chomsky’ego:
- S→CbA∣CaB
- A→CbDA∣CaS∣a
- B→CaDB∣CbS∣b
- Ca→a
- Cb→b
- DA→AA
- DB→BB
13. Postać normalna Greibach
Produkcje są postaci A→aα, gdzie A∈N,a∈T,,α∈N∗.
Określmy jako A-produkcje wszystkie produkcje z nieterminalem A po lewej stronie.
13.1. Lemat#1
Niech G=(N,T,P,S) będzie gramatyką bezkontekstową.
Niech A→α1Bα2 będzie produkcją w P i niech B→β1∣…∣βr będzie zbiorem wszystkich B-produkcji.
Niech G′=(N,T,P′,S) będzie gramatyką otrzymaną z G przez usunięcie produkcji A→α1Bα2 i dodanie produkcji A→α1β1α2∣…∣α1βrα2. Wówczas L(G)=L(G′).
13.1.1. D-d
Dowód po strukturze drzewa wyprowadzenia.
13.2. Lemat#2
Niech G=(N,T,P,S) będzie gramatyką bezkontekstową.
Niech A→Aα1∣…∣Aαr będzie zbiorem tych A-produkcji, których prawe strony zaczynają się od A. Niech A→β1∣…∣βS będzie zbiorem pozostałych A-produkcji. Niech G′=(N∪{B},T,P′,S) będzie gramatyką utworzoną poprzez dodanie nowego nieterminala B i zastąpienie wszystkich A-produkcji przez następujące produkcje A→βi∣βiBB→αj∣αjB1≤i≤s1≤j≤r Wówczas L(G)=L(G′).
13.2.1. D-d
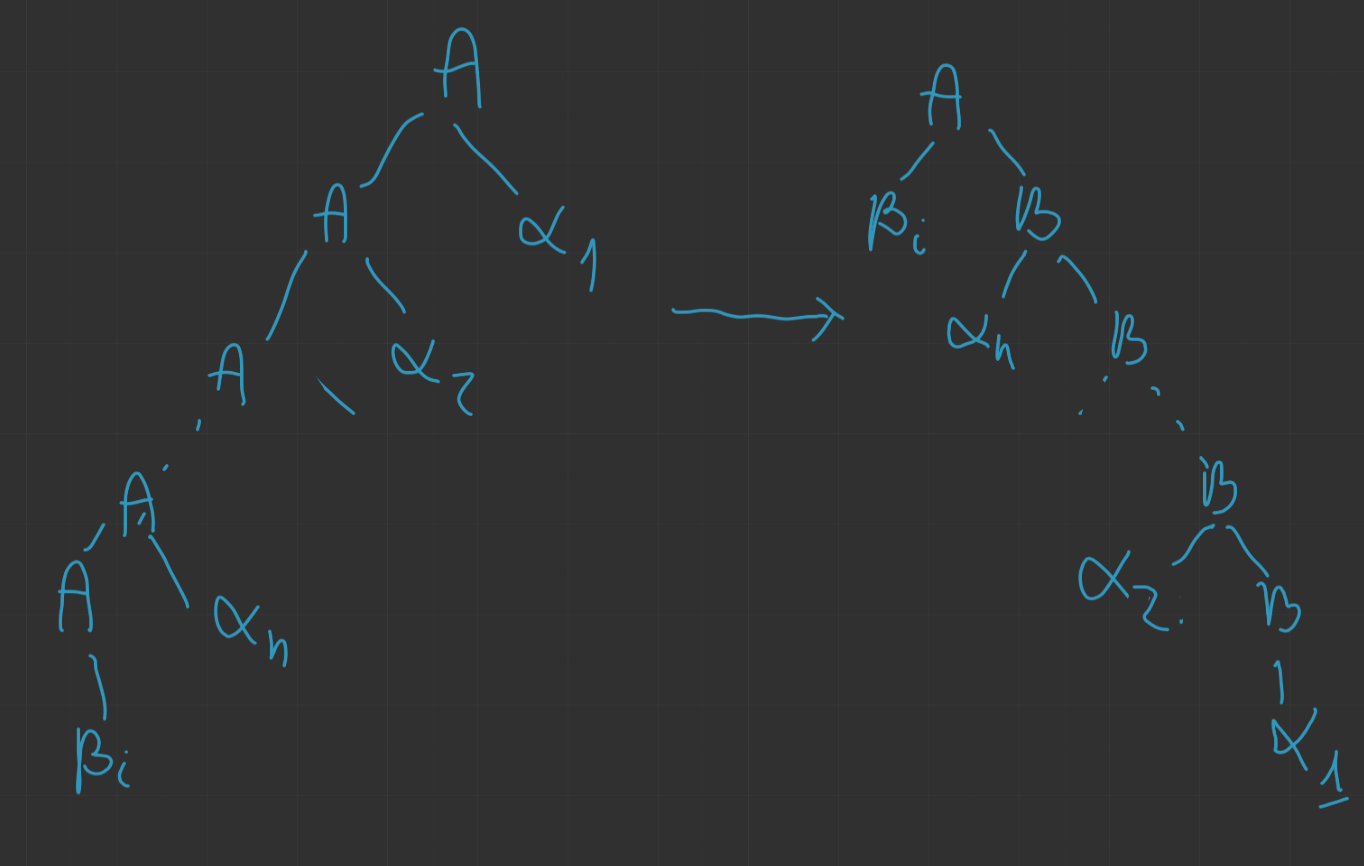
W wyprowadzeniu lewostronnym ciąg produkcji postaci A→Aαi musi kiedyś skończyć się produkcją A→βj: A⇒Aαi1⇒Aαi2αi1⇒⋯⇒Aαin…αi1⇒βjαin…αi1 Można to zastąpić przez A⇒βjB⇒βjαinB⇒⋯⇒βjαin…αi2B⇒Bjαin…αi1
Ponieważ transformacja ta jest obustronna to L(G)=L(G′).
13.3. Twierdzenie#5
Każdy język bezkontekstowy L niezawierający ε jest generowany przez pewną gramatykę, w której każda produkcja jest postaci A→aα, gdzie a∈T,A∈N,α∈N∗.
13.3.1. D-d
Niech G=(N,T,P,S) będzie gramatyką w postaci normalnej Chomsky’ego.
Załóżmy, że N={A1,…,An}.
Modyfikujemy produkcje tak, aby jeśli produkcja jest postaci Ai→Ajα to i<j.
for k←1 to n:
for j←1 to (k−1):
- Za każdą produkcję postaci Ak→Ajα wstaw produkcje Ak→βα dla wszystkich produkcji Aj→β (Lemat#1).
- Dla produkcji postaci Ak→Akα wykonaj Lemat 2 używając nowych nieterminali Bk.
Po wykonaniu tego algorytmu mamy gramatykę równoważną o produkcjach w postaci:
- Ai→Ajγ, gdzie zawsze i<j
- Ai→aγ, gdzie a∈T
- Bi→γ, dzie γ∈(N∪{B1,…,Bi−1})∗.
Zauważmy, że An-produkcje muszą zaczynać się terminalem.
Teraz rozważmy An−1–produkcje: ich lewe strony muszą zaczynać się terminalem lub nieterminalem An więc możemy je z Lematu#1 zastąpić prawymi stronami An-produkcji (wszystkie zaczynają się terminalem). I tak do A1.
Łatwo zauważyć, że B-produkcje nigdy nie zaczynają się nieterminalem B, więc też z Lemat#1 możemy je zastąpić prawymi stronami A-produkcji.
13.4. Przykład
Mamy:
- A1→A2A3
- A2→A3A1∣b
- A3→A1A2∣a
Nie pasuje A3→A1A2 więc z Lemat#1 dostajemy A3→A2A3A2.
Dalej nie pasuje, więc ponownie z Lemat#1 otrzymujemy A3→A3A1A3A2∣bA3A2.
Teraz mamy A3→A3A1A3A2∣bA3A2∣a, korzystamy z Lemat#2 i otrzymujemy
A3→a∣aB3∣bA3A2∣bA3A2B3 oraz B3→A1A3A2∣A1A3A2B3.
Teraz odpowiednio podstawiając zgodnie z Lemat#1 otrzymujemy:
- A3→a∣aB3∣bA3A2∣bA3A2B3
- A2→aA1∣aB3A1∣bA3A2A1∣bA3A2B3A1∣b
- A1→aA1A3∣aB3A1A3∣bA3A2A1A3∣bA3A2B3A1A3∣bA3
- B3→aA1A3A3A2∣aB3A1A3A3A2∣bA3A2A1A3A3A2∣bA3A2B3A1A3A3A2∣bA3A3A2∣aA1A3A3A2B3∣aB3A1A3A3A2B3∣bA3A2A1A3A3A2B3∣bA3A2B3A1A3A3A2B3∣bA3A3A2B3