| lang: ‘pl’ |
| title: ‘Dijkstra’s algorithm’ |
| author: ‘Jerry Sky’ |
| date: ‘2020-05-18’ |
Concept
Algorytm Dijkstry pozwala na znajdowanie najkrótszych ścieżek w grafie G=(V,E,l), gidze l:E→R+. Jest on prostą modyfikacją procedury BFS i w gruncie rzeczy polega na zastąpieniu kolejki FIFO w algorytmie BFS, kolejką priorytetową. Implementacje kolejki priorytetowej na bazie kopca minimalnego zostały przedstawione na poprzednich wykładach.
Implementacja
W algorytmie Dijkstry zostaną użyte następujące operacje na kolejce priorytetowej:
MakeQueue(A) – buduje kolejkę priorytetową z wejściowej tablicy traktując odpowiednie klucze w tablicy A jako priorytety (im mniejszy klucz tym wyższy priorytet).ExtractMin(Q) – zwraca i usuwa z kolejko element o najwyższym priorytecie, czyli w tym przypadku najmniejszym kluczu.DecreaseKey(Q,i) – informuje kolejkę, że element Q[i] ma zmniejszony klucz i w razie potrzeby przesuwa go na odpowiednie miejsce w kolejce.
Dijkstra(G,s):
for all v∈V:
- v.dist←∞
- v.prev←
null
- s.dist←0
- s.prev←s
- Q←
MakeQueue(V)
# używa v.dist jako kluczy w kolejce priorytetowej; im mniejsza wartość dist tym wyższy priorytet
while ∣Q∣>0:
- u←
ExtractMin(Q)
for all (u,v)∈E
if v.dist>u.dist+l(u,v)
- v.dist←u.dist+l(u,v)
- v.prev←u
DecreaseKey(Q,v)
Dla każdego v∈V algorytm Dijkstry zapisuje w v.dist długość najkrótszej ściezki od wierzchołka startwoeg s∈V (jeśli do jakiegoś wierzchołka nie da się dojść od wierzchołka s to długość ta jest ustawiona na ∞). Dodatkowo, dla każdego v∈V w polach v.prev znajduje się wierzchołek, z którego bezpośrednio dojdziemy po najkrótszej ścieżce od s do v. Pozwala nam to na odtworzenie najkrótszych ścieżek od s do dowolnego innego wierzchołka grafu G (jeśli do jakiegoś wierzchołka nie możemy dojść z s to wartość prev pozostanie nullem).
Analogia do budzików w książce Algorithms DPV~ Chapter 4.4.1
Przykład
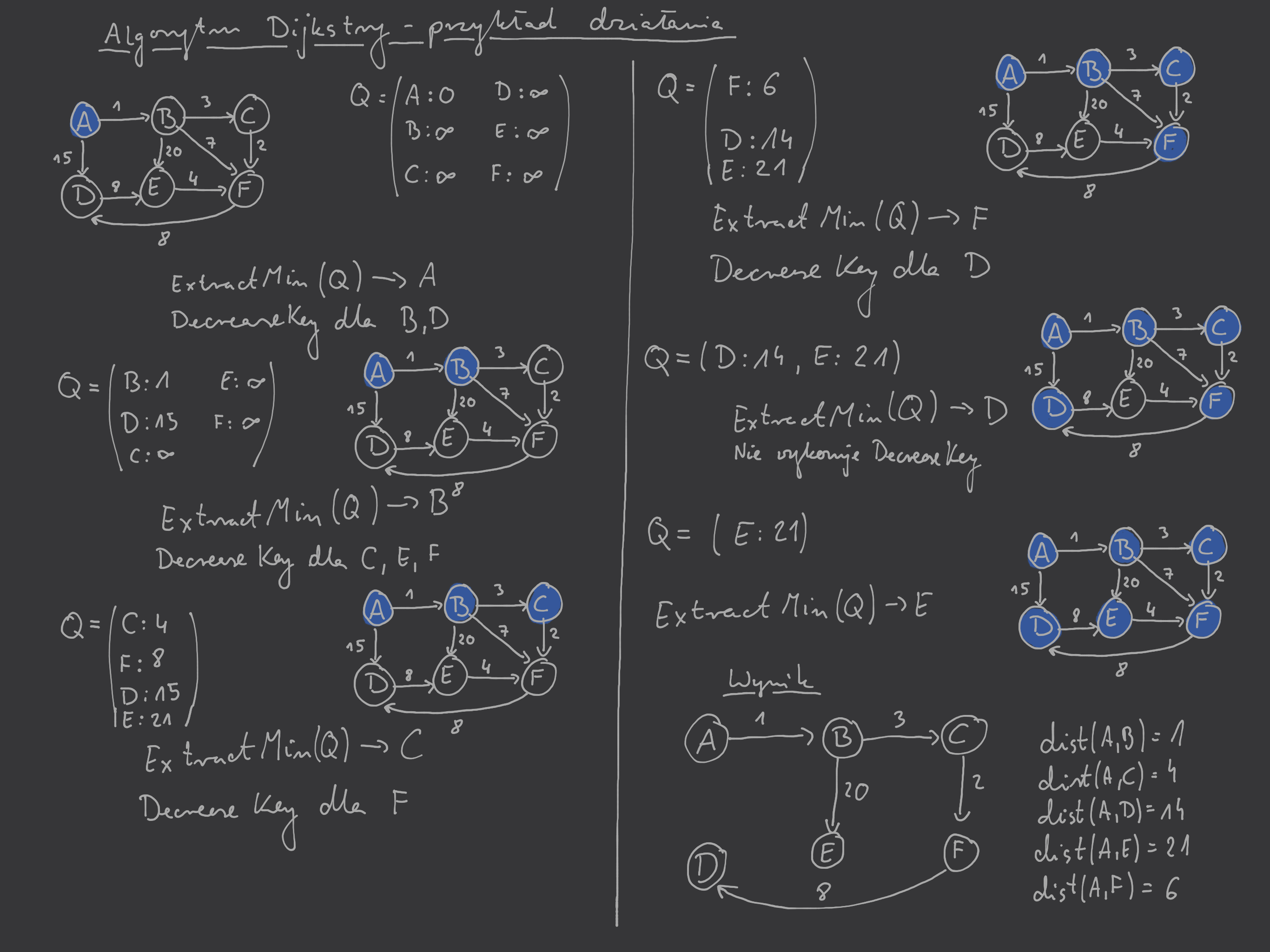
Alternatywna interpretacja
Możemy popatrzeć na problem znajdowania najkrótszej ścieżki w grafie G=(V,E,l) od wierzchołka startowego s∈V jak na powiększanie podzbioru wierzchołków R, dla których znamy już najkrótsze ścieżki.
- Początkowo R=s jest zbiorem zawierającym wierzchołek startowy.
- Powiedzmy, że w pewnym momencie mamy już jakieś wierzchołki w zbiorze R i chcemy go powiększyć o kolejny wierzchołek, który należy do V∖R. Następnym dodanym do R wierzchołkiem (czyli wierzchołkiem, dla którego najkrótsza ścieżka od s jest już znana) powinien być wierzchołek v∈V∖R, którego odległość od wierzchołka startowego s jest najmniejsze spośród wierzchołków należących do R∖V. Wynika to z założenia, że wszystkie krawędzie mają dodatnią wagę i dlatego jeśli v∈V∖R ma najmniejszą odległość od s w zbiorze wierzchołków V∖R to nie jest możliwe znalezienie krótszej ścięzki do niego przechodzącej przez inne wierzchołki należące do V∖R.
W jaki sposób zidentyfikować wierzchołke v, który chcemy dodać do zbioru wierzchołków, dla którego znamy już najkrótsze ścieżki? Rozpatrzmy wierzchołek u, który jest bezpośrednio przed v na najkrótszej ścieżce od s do v. Używając założenia, że wagi krawędzi są dodatnie wiemy, że dist(s,u)<dist(s,v). Oznacza to, że u∈R, bo w przeciwnym wypadku v nie byłby wierzchołkiem najbliższym wierzchołka startowego s spoza zbioru R. Zatem najkrótsza ścieżka od s do v może być wyznaczona przez przedłużenie o jedną krawędź znanej już najkrótszej ścieżki do innego wierzchołka u. Zatem wiemy, że wierzchołek, który będzie dodawany do zbioru R wierzchołków, dla których znamy już najkrótsze ścieżki musi mieć najmniejszą wartość dist(s,u)+l(u,v).
Poprawność działania algorytmu
W celu formalnego udowodnienia poprawności działania algorytmu Dijkstry powinniśmy przeprowadzić dowód indukcyjny (opierający się na rozumowaniu z powyższych punktów) z następującym założeniem indukcyjnym:
Na końcu każdej iteracji pętli while w pseudokodzie algorytmu spełnione są następujące własności:
- Istnieje wartość d, taka że wierzchołki należące do zbioru R (czyli elementy, których nie ma już w kolejce Q), mają odległość ≤d od wierzchołka startowego s.
- Dla każdego wierzchołka u∈V wartość u.dist jest długością najkrótszej ścieżki od s do u, gdzie na ścieżce tej znajdują się tylko wierzchołki należące do zbioru R (jeśli taka ścieżka nei istnieje to u.dist←∞)
Złożoność obliczeniowa
- Na początku (pierwsza pętla
for) inicjujemy wszystkie zmienne co będzie miało złożoność O(∣V∣).
- Procedura
MakeQueue ma złożoność obliczeniową zależącą od implementacji kolejki priorytetowej (np. wykorzystując kopce binarne i BuildHeap mamy złożoność O(∣V∣)), ale ogólnie można ją ograniczyć przez ∣V∣⋅ Insert operacji.
- Następnie w głównej pętli
while wykona się ∣V∣⋅ ExtractMin operacji.
- W wewnętrznej pętli
for wykona się co najwyżej ∣V∣⋅ DecreaseKey operacji.
Zatem w sumie dostajemy górne ograniczenie na złożoność obliczeniową w postaci ∣V∣⋅ Insert +∣V∣⋅ ExtractMin +∣E∣⋅ DecreaseKey.
Porównanie złożoności obliczeniowej algorytmu Dijkstry dla różnych implementacji kolejki priorytetowej:
| Tablica |
O(∣V∣) |
O(1) |
O(∣V∣2) |
| Kopiec binarny |
O(log∣V∣) |
O(log∣V∣) |
O((∣V∣+∣E∣)⋅log∣V∣) |
| Kopiec d-arny |
O(logddlog∣V∣) |
O(logddlog∣V∣) |
O((∣V∣⋅d+∣E∣)⋅logdlog∣V∣) |
| Kopiec Fibonacciego |
O(log∣V∣) |
O(1) (zł. zamortyzowana) |
O(∣V∣log∣V∣+∣E∣) |
Warto zauważyć, że złożoność ta ostatecznie zależy od gęstości grafu (liczby krawędzi do liczby wierzchołków). Zauważmy, że jeśli ∣E∣=Ω(∣V∣2) (graf gęsty) to implementacja kolejki priorytetowej na prostej tablicy ma asymptotycznie najlepszą złożoność. Implementacja przy pomocy kopca binarnego ma lepszą niż przy pomocy tablicy jeśli ∣E∣<log∣V∣∣V∣2. Kopiec d-arny będący uogólnieniem kopca binarnego ma złożoność zależną od d. Jeśli ustalimy d≈∣V∣∣E∣, czyli na średni stopień wierzchołka w grafie wejściowym otrzymujemy implementację, która dla grafów gęstych (czyli takich gdzie ∣E∣=Ω(∣V∣2)) jest asymptotycznie równie dobra jak tablica (złożoność Dijkstry O(∣V∣2)), a dla grafów rzadkich (czyli takich gdzie ∣E∣=O(∣V∣)) jest asymptotycznie równie dobra jak kopiec binarny (złożoność Dijkstry O(∣V∣log∣V∣)). Dodatkowo dla grafów będących pomiędzy (czyli takich gdzie ∣E∣=∣V∣1+δ, δ∈(0,1)) złożoność Dijkstry wynosi asymptotycznie O(∣E∣), czyli jest liniowa względem wielkości grafu. W celu implementacji kolejki priorytetowej można użyć również np. kopca Fibonacciego. Asymptotyczna złożoność zamortyzowana będzie w tym przypadku najlepsza, ale należy pamiętać, że kopiec Fibonacciego jest znacznie bardziej skomplikowaną strukturą, wymaga więcej pracy podczas implementacji i w praktyce często przegrywa z prostszymi strukturami.
More