Problem pokrycia zbioru (set cover) można zobrazować na przykładzie planowania budowy szkół. Powiedzmy, że mamy zbiór wiosek , w których chcemy zbudować szkoły dla okolicznej młodzieży. Musimy przestrzegać następujących założeń:
Celem jest rozmieszczenie szkół w wioskach, aby wszystkie osoby chodzące do szkoły miały ją w odległości nie większej niż ustalona oraz aby wybudować minimalną liczbę szkół. Jeśli dla każdej wioski zdefiniujemy podzbiór wiosek będących w odległości mniejszej niż ustalona od to możemy powiedzieć, że wybudowanie szkoły w wiosce pokrywa osoby z wiosek należących do zbioru .
Input: Zbiór oraz jego podzbiory
Output: Wybór podzbiorów pokrywających zbiór , czyli , gdzie jest zbiorem indeksów
Koszt: – liczba wybranych podzbiorów
Zależy nam na tym, aby koszt wyborów podzbiorów był jak najmniejszy.
Zauważmy, że zachłanne rozwiązanie samo się tutaj nasuwa:
GreedySetCover:
repeat until nie jest całe pokryte:
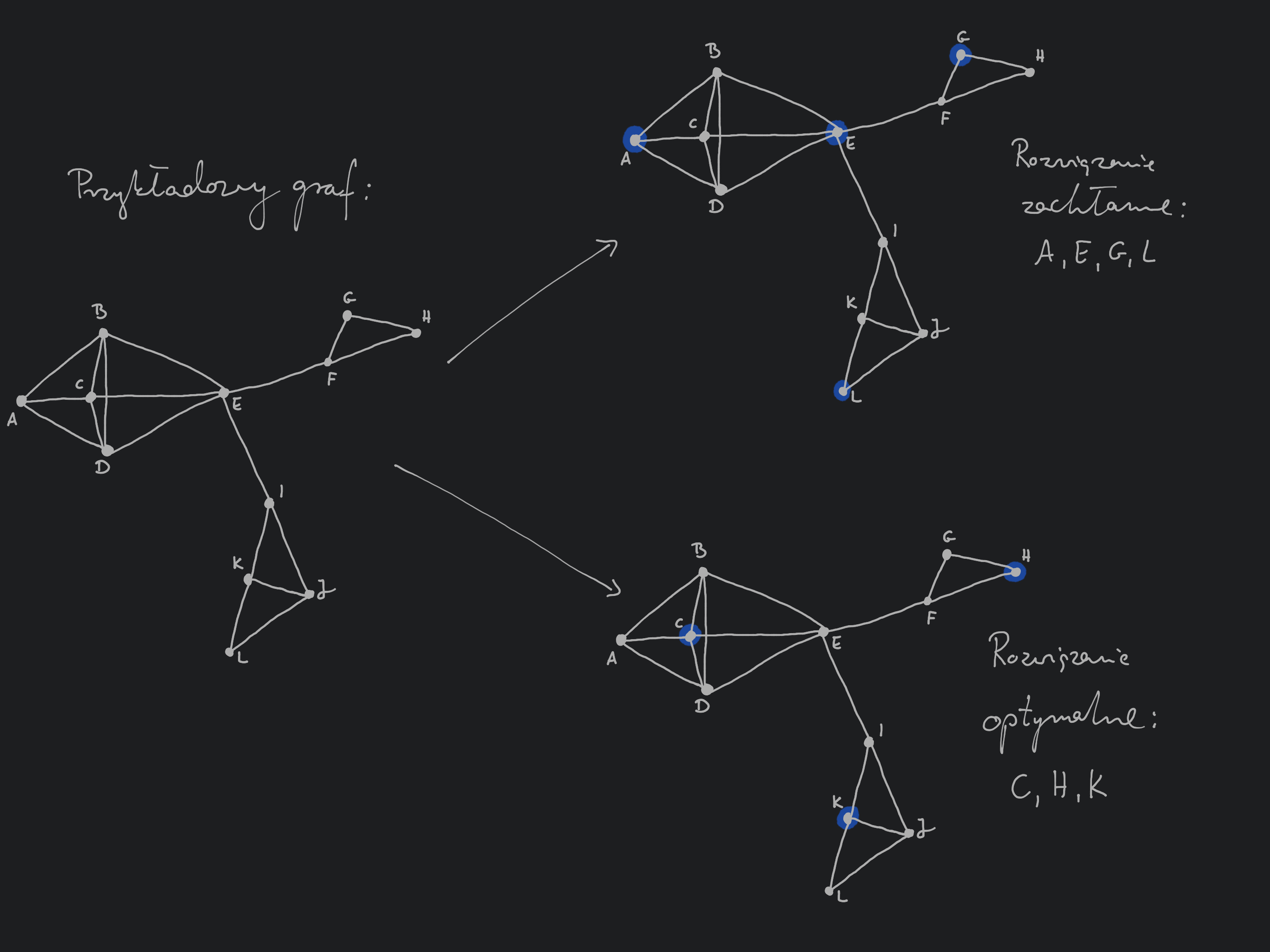
Zobaczmy, jak to naturalne rozwiązanie sprawdza się w praktyce. Wróćmy do naszego przykładu budowy szkół w wioskach. Powiedzmy, że mamy dwunastoelementowy zbiór wiosek: . Łączymy ze sobą te wioski, które są oddalone od siebie o mniej niż ustalona wartość:
Zatem:
górne rozwiązanie (uzyskane w sposób zachłanny) o koszcie to , a dolne rozwiązanie o koszcie (rozwiązanie optymalne) to .
Widzimy zatem, że rozwiązanie zachłanne nie musi dawać nam optymalnego rozwiązania. Na szczęście okazuje się, że jesteśmy w stanie ograniczyć odległość rozwiązania zachłannego od optymalnego w zadowalający sposób.
Załóżmy, że , a optymalne rozwiązanie pokrycia zbioru ma koszt . Wówczas zachłanny algorytm zwróci rozwiązanie o koszcie co najwyżej .
Niech będzie liczbą niepokrytych elementów zbioru po iteracjach pętli algorytmu zachłannego . Skoro niepokryte elementy da się pokryć optymalnymi zbiorami to musi istnieć zbiór mający co najmniej niepokrytych elementów. Zatem możemy ograniczyć wielkość przez
Powtarzając ten argument uzyskujemy ograniczenie:
Użyjmy znanego ograniczenia , które daje nam:
Zauważmy, że dla dostajemy , co oznacza, że po krokach algorytm zachłanny pokryje wszystkie elementy zbioru wejściowego.
Algorytm zachłanny rozwiązujący problem pokrycia zbioru należy do klasy algorytmów aproksymujących (czyli niekoniecznie zwracających optymalne rozwiązanie), a stosunek rozwiązania otrzymanego przy pomocy algorytmu aproksymacyjnego przez rozwiązanie algorytmu optymalnego nazywamy approximation factor. Powyższy algorytm zachłanny dla problemu pokrycia zbioru ma approximation factor równy . Innymi metodami można pokazać również, że nie istnieje algorytm wielomianowy mający mniejszy approximation factor.