Schemat kompresji MP3 w sporym uproszczeniu składa się z trzech kroków:
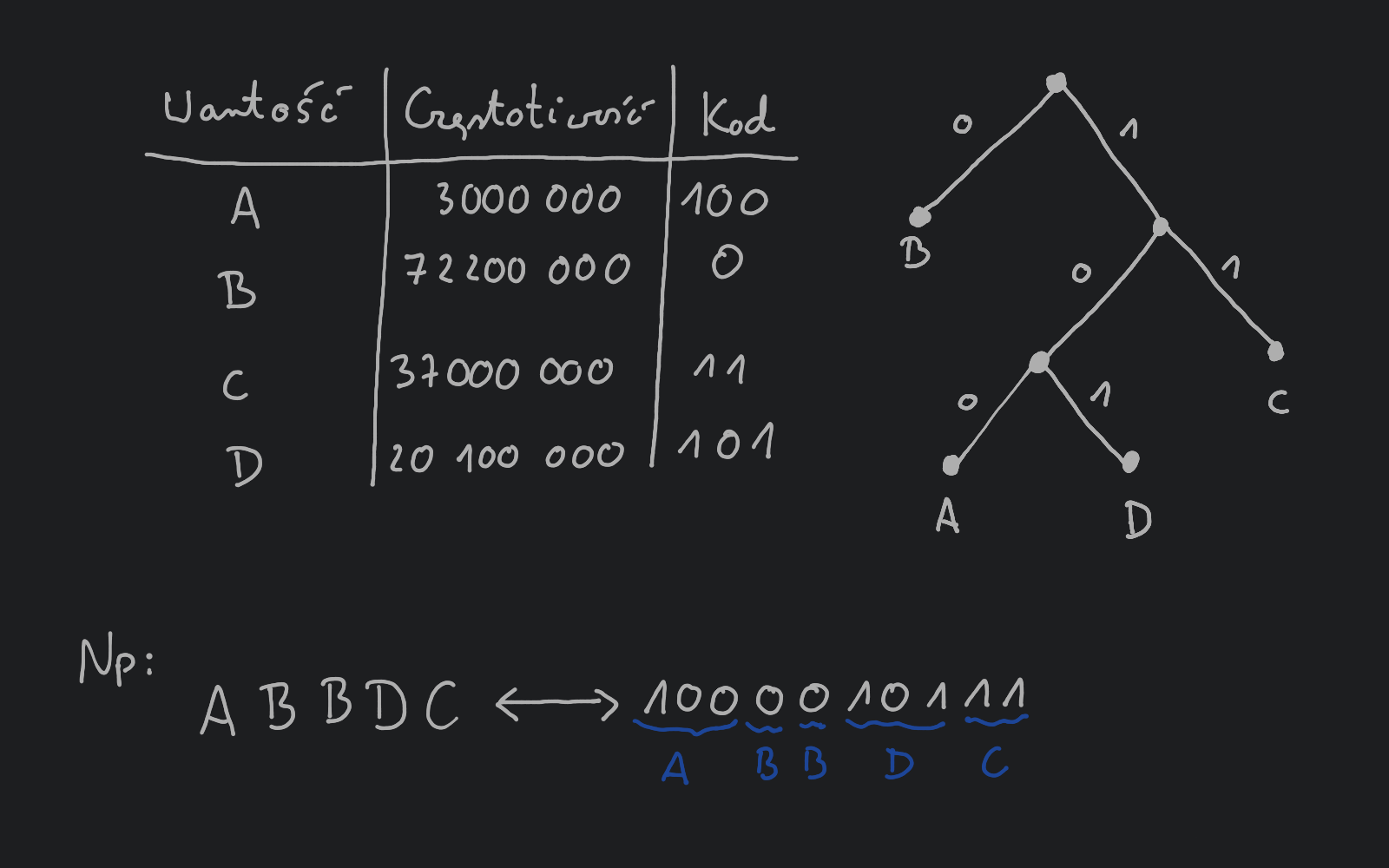
Przyjrzyjmy się temu ostatniemu krokowi. Powiedzmy, że jest czteroelementowym zbiorem. Najprostszy sposób opisania ciągami bitowymi wartości ze zbioru będzie nadanie kolejnych dwu-bitowych kodów np. w następujący sposób: będzie miało kod , będzie miało kod , będzie miało kod , a będzie miało kod . Zatem zapisanie przykładowych 50 minut muzyki będzie wymagało megabitów. Zauważmy, że odczytanie ciągu bitowego odpowiadającego ciągowi wartości ze zbioru jest łatwe: czytamy ciąg bitowy od początku do końca biorąc po 2 bity i konwertując je na wartości ze zbioru .
Zastanówmy się, czy da się zapisać interesujący nas ciąg w bardziej efektywny sposób (przy użyciu mniejszej ilości bitów)? Możemy to uczynić posiadając dodatkową informację, np. w postaci częstotliwości występowania w interesującym nas ciągu wartości ze zbioru . Powiedzmy, że wartość występuje razy, występuje razy, występuje razy, a występuje razy.
Idea pozwalająca na lepszą kompresję ciągu polega na tym, że częściej występującej wartości chcemy nadać kod bitowy o mniejszej liczbie bitów, czyli będziemy stosowali kodowanie o zmiennej liczbie bitów.
Zauważmy, że to wiąże się z możliwymi problemami z konwersją ciągu bitowego z powrotem na wartości ze zbioru . Dla przykładu, jeśli wartości nadamy kod wartości kod , a wartości kod i otrzymamy ciąg to nie jesteśmy w stanie stwierdzić, czy to jest zapis ciągu , czy może ?
Rozwiązaniem tego problemu są kody prefiksowe, czyli takie, że żaden kod nie jest prefiksem innego kodu.
Teraz możemy już zdefiniować problem, który znany jest jako kodowanie Huffmana:
Input: tablica częstotliwości wartości ze zbioru , gdzie .
Output: prefiksowe kody binarne przypisane do wartości ze zbioru minimalizujące długość ciągu bitowego odpowiadającemu ciągowi o wejściowych częstotliwościach.
Zauważmy, że ukorzenione drzewo binarne (czyli takie, którego węzły mają dwóch potomków lub są liśćmi) może reprezentować kodowanie prefiksowe w następujący sposób:
Drzewo kodowe dla wcześniej zaprezentowanego przykładu:
Dla przykładowego drzewa kodowego długość wyjściowego kodu będzie wynosić megabitów, czyli ponad lepiej niż poprzednio.
Zauważmy, że aby wykonać konwersję kodu binarnego na wartości ze zbioru wystarczy przejść wielokrotnie drzewo od korzenia do liścia, tak że jeśli trafimy na to przechodzimy do lewego potomka, jeśli trafimy na to przechodzimy do prawego potomka, a jeśli dotrzemy do liścia to zapisujemy odpowiadającą mu wartość.
Formalnie optymalne kodowanie jest takie, które będzie minimalizować długość ciągu binarnego odpowiadającemu ciągowi wartości ze zbioru , czyli:
Możemy zauważyć, że dla każdej wartości długość kodu bitowego odpowiadającego jest równa głębokości liścia odpowiadającego wartości w drzewie kodowym. Zatem możemy zapisać długość kodu całego ciągu jako:
Powyższy wzór mówi nam, że dwa symbole z najmniejszą częstotliwością muszą występować w drzewie kodowym, bo w przeciwnym przypadku możemy otrzymać tylko większą długość kodu całego ciągu. Obserwacja ta może być podstawą do pierwszego zachłannego kroku budowy drzewa kodowego.
Zauważmy również, że możemy zdefiniować częstotliwość węzłów wewnętrznych drzewa, która będzie równa sumie częstotliwości potomków danego węzła. Częstotliwość ta odpowiada dokładnie ile razy dany wierzchołek będzie odwiedzony podczas przechodzenia drzewa przy konwersji kodów. Zatem możemy jeszcze inaczej zapisać długość ciągu binarnego na wyjściu: gdzie jest drzewem kodowym, jest częstotliwością węzła należącego do drzewa . Do długości kodu nie dodajemy częstotliwości korzenia drzewa, ponieważ (jak wcześniej zostało to zdefiniowane) przejście krawędzi odpowiada bitowi lub , więc będąc w korzeniu nie dokładamy bitów do ciągu wyjściowego.
Wykorzystując powyższe obserwacje możemy skonstruować algorytm zachłanny budujący optymalne drzewo kodowe, a co za tym idzie kody binarne przypisane do wartości ze zbioru w następujący sposób:
Huffman:
for to :
insertfor to :
ExtractMinExtractMininsertZłożoność obliczeniowa: Używając np. kopca binarnego w celu implementacji kolejki priorytetowej otrzymujemy algorytm o złożoności , bo w pętlach długości wykonujemy stałą liczbę operacji o złożoności .