Cały kod źródłowy jest zawarty głównie w funkcji main.cpp, ex-1.cpp, ex-2.cpp oraz plikach w katalogu shared.
W celu kompilacji programu należy użyć make main.out. (Możliwe jest uprzednie posprzątanie make clean)
Żeby uruchomić program należy użyć ./main.out <params>, gdzie <params>:
--type - uruchom program z algorytmem:
quick dla QuickSort (domyślny)insert dla InsertSortmerge dla MergeSortdual-pivot-quick dla DualPivotQuickSort--comp - kolejność elementów:
'>=' malejąca'<=' rosnąca (domyślna)--stat nazwa_pliku k
nazwa_pliku plik do którego program ma zapisać statystykik ile razy ma wykonać pętlę opisaną w zadaniuCelem zadani jest zaimplementowanie i przetestowanie następujących algorytmów sortowania:
- InsertionSort
- MergeSort
- QuickSort
Program przyjmuje dwa parametry wejściowe
--type insert|merge|quick– określający wykorzystywany algorytm sortowania oraz--comp '>='|'<='– określający porządek sortowania.
Wejściem dla programu są kolejno:
- liczba – długość sortowanej tablicy
- tablica elementów do posortowania (niech elementy tej tablicy zostaną nazwane kluczami).
Program powinien sortować tablicę wybranym algorytmem i wypisywać na standardowym wyjściu błędów wykonywane operacje (porównania, przestawienia). Po zakończeniu sortowania, na standardowym wyjściu błędów powinna zostać wypisana łączna liczba porównań między kluczami, łączna liczba przestawień kluczy oraz czas działania algorytmu sortującego. Finalnie, program sprawdza, czy wynikowy ciąg jest posortowany zgodnie z wybranym porządkiem, a następnie wypisuje na standardowe wyjście liczbę posortowanych elementów oraz posortowaną tablicę.
Przykładowe wywołanie:./main --type quick --comp '>=' 5 9 1 -7 1000 4
Uzupełnij program z zadania 1 o możliwość wywołania go z dodatkowym parametrem uruchomienia
--stat nazwa_pliku k, wtedy pomija on wczytywanie danych i dla każdego wykonuje po niezależnych powtórzeń:
- generowania losowej tablicy elementowej (zadbaj o dobry generator pseudo-losowy)
- sortowania kopii wygenerowanej tablicy
- dla każdego z sortowań, zapisania do pliku
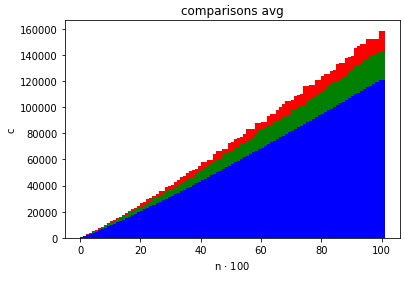
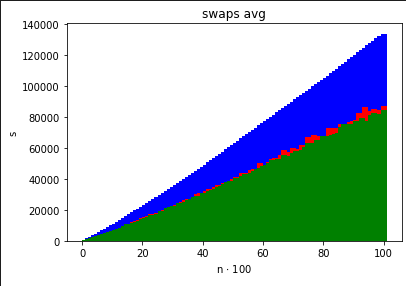
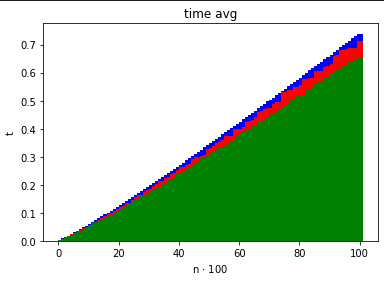
nazwa_plikustatystyk odnośnie rozmiaru danych , liczby wykonanych porównań między kluczami, liczby przestawień kluczy oraz czasu działania algorytmu sortującego.Po zakończeniu programu, korzystając z zebranych danych przedstaw na wykresach, za pomocą wybranego narzędzia (np.
numpy, Matlab, Mathematica):
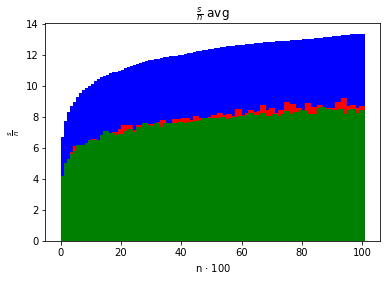
- średnią liczbę wykonanych porównań kluczy w zależności od ,
- średnią liczbę przestawień kluczy w zależności od
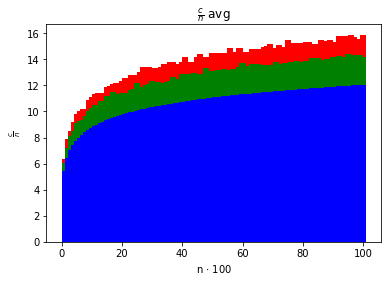
- średni czas działania algorytmu w zależności od iloraz w zależności od iloraz w zależności od
Zadbaj o to, by dane dotyczące różnych algorytmów sortujących można było nakładać na te same osie i porównywać. Sprawdź, jak wykresy zmieniają się dla różnych (np. ).
Wykresy wykonałem w Jupyter Notebook (numpy) na podstawie logów wygenerowanych przy pomocy mojego programu.
Zrzuty ekranu wykresów są dostępne bezpośrednio w Jupyter Notebook albo poniżej:
gdzie:
QuickSortDualPivotQuickSortMergeSortInsertionSort (nie wyświetlony, bo ma za duże wartości w porównaniu do innych)Istnieje możliwość zobaczenia jak zadziałał InsertionSort po uruchomieniu go w Jupyter Notebook (odkomentowanie odpowiednich linijek) jednakże wszystkie wykresy wskazują na to, że InsertionSort jest najgorszym algorytmem z wszystkich:
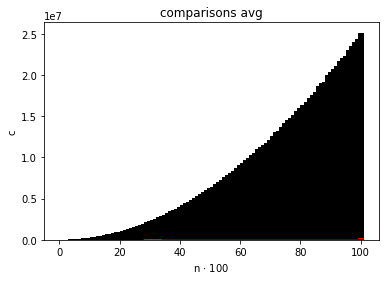
jako, że pozostałych wykresów praktycznie nie widać bo są tak małe w porównaniu z InsertionSortem.
Uzupełnij zadanie 1 o algorytm Dual-pivot QuickSort używając strategii Count:
- Mamy dwa pivoty i oraz załóżmy, że .
- Załóżmy, że w procedurze
partitionklasyfikując -ty element tablicy mamy elementów małych (mniejszych od ) oraz elementów dużych (większych od ).- Jeśli : porównuj -ty element w pierwszej kolejności z , a następnie, jeśli jest taka potrzeba, z .
- Jeśli : porównuj -ty element w pierwszej kolejności z , a następnie jeśli jest taka potrzeba z .
Dokonaj szczegółowych porównań otrzymanych statystyk dla algorytmu QuickSort i Dual-pivot QuickSort. Eksperymentalnie wyznacz stałą stojącą przy czynniku dla liczby porównań między kluczami.
Stała przy n ln(n) dla QuickSorta wyniosła 1.6554738137365612
za to dla DualPivotQuickSorta wyniosła 1.5186710672510784.